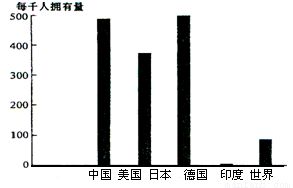
根據(jù)題目所提供的信息,某跨國公司在對(duì)部分國家進(jìn)行產(chǎn)品普及率調(diào)查統(tǒng)計(jì)后,決定在中國北京投資建廠。需要回答的第一個(gè)問題是:生產(chǎn)該產(chǎn)品的工廠最有可能是 a.自行車廠 還是 b.汽車制造廠?
解題分析
1. 決策背景理解:
跨國公司決定在中國北京投資建廠,是基于對(duì)“部分國家使用該公司產(chǎn)品的普及率”所做的調(diào)查統(tǒng)計(jì)。這意味著該產(chǎn)品在全球不同國家的市場滲透率存在差異,而調(diào)查數(shù)據(jù)支持其在中國投資生產(chǎn)的決策。
- 工廠類型推斷:
- 自行車廠:自行車作為一種基礎(chǔ)代步工具,在發(fā)展中國家普及率通常較高,且生產(chǎn)技術(shù)相對(duì)成熟,市場競爭激烈。北京作為中國一線城市,交通壓力大,自行車(含共享單車)雖有市場,但通常此類產(chǎn)品的制造基地可能更傾向于成本較低的二三線城市或工業(yè)區(qū)。
- 汽車制造廠:汽車屬于高價(jià)值、高技術(shù)含量的消費(fèi)品,其普及率與國家經(jīng)濟(jì)發(fā)展水平、居民收入密切相關(guān)。中國作為全球最大的汽車市場之一,普及率仍有增長空間(尤其相比發(fā)達(dá)國家)。北京及周邊區(qū)域(如河北、天津)已形成汽車產(chǎn)業(yè)集群,具備完整的供應(yīng)鏈、技術(shù)人才和市場輻射能力。跨國公司若調(diào)查發(fā)現(xiàn)中國汽車普及率相對(duì)較低(或處于快速增長期),且自身產(chǎn)品具有競爭力,則投資建廠符合市場擴(kuò)張邏輯。
- 關(guān)鍵線索:
- 題目強(qiáng)調(diào)“普及率調(diào)查統(tǒng)計(jì)”,暗示該產(chǎn)品在目標(biāo)國家的普及率可能存在較大差距,屬于“成長型市場”。
- 北京作為首都,具有高技術(shù)產(chǎn)業(yè)導(dǎo)向、政策支持、消費(fèi)市場龐大等特點(diǎn),更符合汽車制造這類資本與技術(shù)密集型產(chǎn)業(yè)的選址需求。
- 結(jié)合現(xiàn)實(shí)背景,許多跨國汽車企業(yè)(如奔馳、寶馬、現(xiàn)代等)均在中國設(shè)廠,以貼近市場、降低成本,而自行車制造則較少由跨國公司以“普及率調(diào)查”為導(dǎo)向進(jìn)行重大投資。
結(jié)論
綜合以上分析,生產(chǎn)該產(chǎn)品的工廠最有可能是 b.汽車制造廠。因?yàn)槠嚠a(chǎn)品的普及率與經(jīng)濟(jì)發(fā)展階段緊密相關(guān),中國市場潛力巨大,且北京具備汽車制造業(yè)所需的產(chǎn)業(yè)基礎(chǔ)與區(qū)位優(yōu)勢,符合跨國公司基于全球普及率差異進(jìn)行產(chǎn)能布局的典型戰(zhàn)略。