信誠全球商品主題證券投資基金(LOF)2013年半年度報告摘要,為我們揭示了該基金在上半年全球宏觀經濟復雜多變、商品市場波動加劇背景下的投資策略與績效表現。報告的核心章節之一“項目投資”,系統闡述了基金管理團隊在大宗商品及相關領域的具體資產配置、行業選擇與風險控制邏輯。
一、 投資策略與市場環境
2013年上半年,全球經濟增長呈現分化格局,美國經濟復蘇跡象逐步明朗,而歐元區仍深陷債務危機陰霾,新興市場經濟增速普遍放緩。在此背景下,大宗商品市場整體承壓,但內部結構分化顯著。貴金屬如黃金,因市場對美聯儲量化寬松政策退出的預期升溫而大幅調整;工業金屬則受中國需求放緩影響表現疲軟;能源類商品如原油價格相對堅挺,但波動加大;農產品表現則受特定氣候與供需因素主導,呈現差異化走勢。
信誠全球商品主題基金(LOF)作為一只專注于全球商品市場的上市型開放式基金,其投資范圍涵蓋商品類上市公司股票、商品類ETF及衍生品等。在2013年上半年,基金管理團隊秉持“自上而下”的宏觀分析與“自下而上”的個股精選相結合的策略,靈活調整資產組合,以應對市場的劇烈波動。
二、 項目投資組合結構分析
根據半年度報告摘要,基金在“項目投資”上的布局主要呈現以下特點:
- 行業配置側重清晰:基金重點配置于能源(特別是油氣勘探、生產與服務公司)、基本金屬與礦業、以及部分農產品產業鏈相關企業。這種配置反映了團隊對當時全球經濟“弱復蘇”格局下,剛性需求相對較強的能源板塊,以及具備長期資源稀缺性邏輯的礦業板塊的偏好。適度分散投資于農業領域,以對沖單一行業風險。
- 地域分布多元化:投資標的覆蓋全球多個主要資源產區與消費市場,包括北美、澳洲、拉美、非洲及部分新興市場。這種地域分散有助于降低單一國家或地區的政治、政策及運營風險。例如,加大了對北美頁巖油氣革命相關受益公司的配置,同時關注拉美等資源富集地區的礦業龍頭。
- 投資工具運用靈活:除了直接投資于商品生產商的股票,基金也審慎運用了商品ETF、結構性票據等工具,以更高效地捕捉大宗商品價格波動的機會,并進行流動性管理和風險對沖。
三、 核心投資邏輯與風險控制
報告摘要顯示,基金的投資邏輯建立在深入的基本面研究之上:
- 供給端分析:密切關注全球主要礦藏的開采成本、資本開支周期、地緣政治對供給的擾動(如中東局勢對原油的影響)。
- 需求端研判:緊密跟蹤中美歐等主要經濟體的工業活動、基建投資及消費數據,預判其對工業金屬、能源等的需求變化。
- 金融屬性考量:分析美元匯率走勢、全球利率環境及通脹預期對商品金融定價的影響。
在風險控制方面,基金通過嚴格的下行風險監測、倉位動態調整以及止損紀律,力求在商品市場的高波動特性中控制回撤。半年度報告也坦誠指出了上半年面臨的主要挑戰,包括金價暴跌對貴金屬持倉的沖擊,以及部分新興市場貨幣貶值帶來的匯率風險。
四、 績效回顧與未來展望
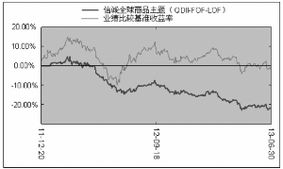
盡管面臨不利的市場環境,報告摘要顯示,基金通過積極的資產配置和個股選擇,在一定程度上抵御了市場系統性下跌的風險,其表現與業績比較基準的對比情況在報告中得以體現。展望下半年,管理團隊表示將繼續聚焦于全球宏觀經濟走勢、主要央行的貨幣政策動向以及重要商品的具體供需平衡表,尋找被市場低估的投資機會,并保持組合的靈活性與韌性。
信誠全球商品主題證券投資基金(LOF)2013年半年度報告中的“項目投資”部分,詳盡展示了一只專業商品基金在復雜市況中的實戰布局與思考。它不僅是一份投資記錄,更為投資者理解全球商品市場的投資脈絡與基金管理人的專業能力提供了寶貴的視角。